Articles
KCAPTCHA project
Donate
Русский
Protection against recognition
How to draw recognition-protected images? At first, we must answer to question "how images being recognized usually". Then we can realize, how we can make more difficult this recognition.
Contrary to common opinion, for CAPTCHA defeating, as usual, they do not use scanned text recognition software as MS Office Document Imaging etc. So, if your CAPTCHA does not recognized by that software, it does not mean, that the text can't be easily read by specially designed bot (see "Defeating examples").
Recognition usually divided into 2 main stages:
- Each symbols location finding.
- Recognition of each found symbol.
If symbols has constant positions (as in Invision Power Board forum CAPTCHA—see picture at right), only second stage remains. So we must vary symbol positions at least.
If symbol positions are not constant, next way for symbols finding is comparing with background by contrast. If symbols color differs background one, (as phpBB forum has), it does not give any protection:
→

We leave only dark pixels—and "voila".
Symbol locations marked by yellow color (rectangles which includes "dark pixels")
Thus, we must add noise that can't be easily separated from symbols, or we must make difficulties for symbols separation each from each, connecting or intersecting its.
Symbol recognition in essence may be carried out by various ways.
Simplest one—per-pixel comparing. We compare each symbol with one from etalon font. And select symbol with maximal coincidence.
CAPTCHA is vulnerable to per-pixel comparing if one does not use geometric distortion of symbols and uses one font (or very few fonts).
Other, more sophisticated algorithms recognizes symbol by its peculiarities: branching, closed areas... There is class of algorighms named "neural networks". It is a "black box", trained to linking input shape with output answer. However, training procedure is usually lengthy and laborious.
For protection against these algorithm one can add noise disfigures symbol shape, but we can receive image unreadable by human.
In my opinion, especial attention must be paid to first protection point: against symbol bounds determination—it is diffucult to recognize symbol if we do not know where it starts and ends.
Let's see applying these principles on examples of real CAPTCHAs (stars show my own estimation of strength, from 1 to 4):
 |
Google *** Non-linear distortion, symbols can slightly displace one from one, variating of fonts. No noise. Symbols often not connect and can easily be selected one from one. |
| MSN **** Rotating and distortion, noise: lines with same color intersecting symbols. | |
 |
Yahoo *** Non-linear distortion, noise: polylines intersecting symbols. Polyline sometimes may be separated from symbols. |
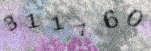 |
Mail.ru old ** Symbol rotation, few fonts, contrast with background. |
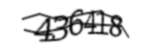 |
Mail.ru **** Displacing by height, non-linear distortion, polylines intersecting text. |
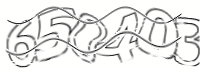 |
Yandex **** Gluing of outline symbols, non-linear distortion, noise with white and black lines. |
| Rambler ** Multicolor symbols, rotation, displacing. Noise. | |
| Beeline*** Minor linear distortion. Noise with inverted ellipses. | |
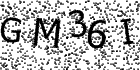 |
MTS old ** Minor rotation, displacing. Noise can be easily removed by blurring. Pretty weak CAPTCHA. |
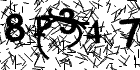 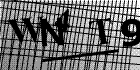 |
MTS *** Minor rotation, displacing. Seldom intersection. Fonts. Intensive noise, both background texture and lines lays on symbols. But sometimes image is human unreadable. |
 |
Megafon *** Displacing, noise with lines and pixels. |
| Skylink * Very bad CAPTCHA: constant font, constant symbol positions. Can be easily recognized by per-pixel comparing. |